第一章 单元测试
1、单选题:以下()不是金融数据的特点?
A:准确性高
B:数据频度低
C:数据量大
D:非平稳
正确答案:【数据频度低
】
2、单选题:在同一时间,不同统计单位相同统计指标组成的数据列,数据按照统计单位进行排列是()。
A:面板数据
B:平行数据
C:时间序列数据
D:横截面数据
正确答案:【横截面数据
】
3、单选题:山东省所有城市2010-2020年年度降雨量所构成的数据,其数据类型是()。
A:时间序列数据
B:面板数据
C:横截面数据
D:组合数据
正确答案:【面板数据
】
4、单选题:对金融计量模型进行序列相关检验、异方差性检验和多重共线性检验等属于()检验。
A:计量经济学
B:统计
C:经济意义
D:经济适用性
正确答案:【计量经济学
】
5、单选题:Eviews按照操作互动性来划分,属于()模式的计量软件。
A:命令行
B:菜单
C:点选
D:中间
正确答案:【中间
】
6、多选题:对金融计量模型进行检验应该包括()方面的检验。
A:经济意义检验
B:计量经济学检验
C:统计检验
D:经济适用性检验
正确答案:【经济意义检验
;计量经济学检验
;统计检验
】
7、多选题:在金融计量建模中可以使用的金融计量软件种类繁多,并且随着技术的进步不断升级。这些软件可以按操作的互动性与否分为()三种模式。
A:菜单模式
B:中间模式
C:点选模式
D:命令行模式
正确答案:【菜单模式
;中间模式
;命令行模式
】
8、判断题:为了能更高研究金融规律,金融计量学要求所建立的模型需要对真实世界的金融问题实现完全模拟。()
A:对
B:错
正确答案:【错】
9、判断题:中国每年的通货膨胀率数据是一个横截面数据。()
A:错
B:对
正确答案:【错】
10、判断题:中国、日本、韩国三国2020年的GDP数据构成了平行数据。()
A:错
B:对
正确答案:【错】
第二章 单元测试
1、单选题:球的表面积公式是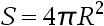 ,那么表面积S和半径R的关系是()。
,那么表面积S和半径R的关系是()。
A:回归关系
B:非线性相关关系
C:线性相关关系
D:函数关系
正确答案:【函数关系
】
2、单选题:对于一元线性回归模型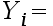
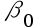 +
+ 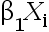 ,参数估计量
,参数估计量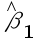 显著性检验构造的t统计量及服从的分布分别是()。
显著性检验构造的t统计量及服从的分布分别是()。
A: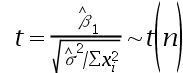
B: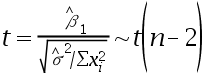
C: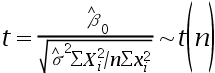
D: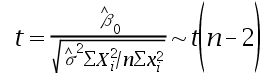
正确答案:【
】
3、单选题:一元线性回归模型中,方差的最小二乘估计量是()。
A: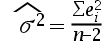
B: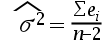
C: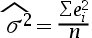
D: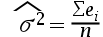
正确答案:【
】
4、单选题:一元线性回归模型中,最小二乘估计量的大样本性质包括()。
A:其他都是
B:一致性
C:渐近无偏性
D:渐近有效性
正确答案:【其他都是
】
5、单选题:拟合优度被定义为()。
A: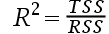
B: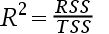
C: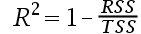
D: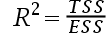
正确答案:【
】
6、多选题:一元线性回归模型中,最小二乘估计量的小样本性质包括()。
A:线性性
B:有限性
C:有效性
D:无偏性
正确答案:【线性性
;有效性
;无偏性
】
7、多选题:为什么要设定随机误差项,原因包括()。
A:代表众多细小的因素
B:代表误差
C:代表未知的因素
D:代表残缺数据
正确答案:【代表众多细小的因素
;代表误差
;代表未知的因素
;代表残缺数据
】
8、判断题:增大样本容量、提高拟合优度能显著增宽参数的置信区间。()
A:对
B:错
正确答案:【错】
9、判断题:假设检验的核心思想就是利用样本信息来判断原假设是否合理,逻辑推理方法是反证法。()
A:错
B:对
正确答案:【对】
10、判断题: 也是一个随机变量。()
也是一个随机变量。()
A:对
B:错
正确答案:【对】
第三章 单元测试
1、单选题:在多元线性回归模型中,随机误差项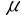 的方差的无偏估计量为()。
的方差的无偏估计量为()。
A: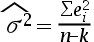
B: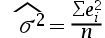
C: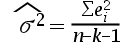
D: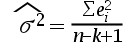
正确答案:【
】
2、单选题:对于多元线性回归模型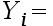
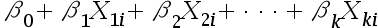 ,样本最小容量为()。
,样本最小容量为()。
A:k+1
B:k
C:3(k+1)
D:30
正确答案:【k+1
】
3、单选题:在常见的几个信息准则中,()对自由度减少的惩罚是最严厉的。
A:AIC
B:DW
C:SC
D: HQIC
HQIC
正确答案:【SC
】
4、单选题:在多元线性回归模型中,解释变量X是之间互不相关,即无多重共线性,用矩阵的语言进行表示就是()。
A:解释变量矩阵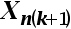 是非奇异的
是非奇异的
B:解释变量矩阵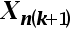 是行满秩的
是行满秩的
C:解释变量矩阵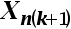 是奇异矩阵
是奇异矩阵
D:解释变量矩阵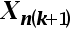 是列满秩的
是列满秩的
正确答案:【解释变量矩阵是列满秩的
】
5、单选题:Theil不相等系数U越接近于(),则模型的预测能力最好。
A:0.5
B:0
C:1
D:1.5
正确答案:【0
】
6、多选题:试研究一样本,样本区间为2000年1月到2019年12月,如果我们以2000年1月到2016年12月的数据来拟合模型,然后来预测2016年12月到2019年12月的结果,据此与真实值来进行对比,判断模型的拟合效果如何,这种预测方式叫做()。
A:事前预测
B:样本内预测
C:事后模拟
D:样本外预测
正确答案:【事前预测
;样本外预测
】
7、多选题:以下()是一个“好”的模型所应该具有的特征。
A:节省性
B:高拟合性
C:预测能力强
D:理论一致性
正确答案:【节省性
;高拟合性
;预测能力强
;理论一致性
】
8、判断题:MSE越大,则MAE就越大。()
A:错
B:对
正确答案:【对】
9、判断题:在多元回归模型中,调整后的拟合优度越大,方程整体的显著性检验越容易通过。()
A:错
B:对
正确答案:【对】
10、判断题:如果在模型中增加解释变量,拟合优度就会变大,所以增加解释变量会提高模型的解释能力。()
A:错
B:对
正确答案:【错】
第四章 单元测试
1、单选题:Spearman检验法为什么不能直接使用随机误差项μ与解释变量X的相关系数来进行判定呢?原因是()。
A:在OLS估计方法下,相关系数始终为0无法判断
B:Spearman提出的相关系数计算方法精度更高
C:在多元回归模型中,解释变量X有多个,不知道和哪个来计算相关系数
D:相关系数计算出来误差过大
正确答案:【在OLS估计方法下,相关系数始终为0无法判断
】
2、单选题:怀特检验的统计量是()。
A: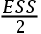 ,其中ESS是原回归函数的解释平方和
,其中ESS是原回归函数的解释平方和
B: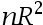 ,其中n为样本容量,
,其中n为样本容量,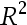 为原回归函数的拟合优度
为原回归函数的拟合优度
C: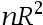 ,其中n为样本容量,
,其中n为样本容量,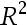 为辅助回归函数的拟合优度
为辅助回归函数的拟合优度
D: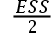 ,其中ESS是辅助回归函数的解释平方和
,其中ESS是辅助回归函数的解释平方和
正确答案:【,其中n为样本容量,为辅助回归函数的拟合优度
】
3、单选题:对于异方差检验的解析法,核心思想都是一致的,即()。
A:判断解释变量的方差与被解释变量之间的相关性
B:判断随机误差项的方差与解释变量之间的相关性
C:判断随机误差项之间的相关性
D:相关系数法检验
正确答案:【判断随机误差项的方差与解释变量之间的相关性
】
4、单选题:在G-Q检验法中,为什么要将样本中居中的d项观测数据除去?原因是()。
A:可以使两组的数据区分度更大
B:中间的数据基本都存在变异性,去除效果会更好
C:减少模型的自由度
D:增加模型的自由度
正确答案:【可以使两组的数据区分度更大
】
5、单选题:在因变量y与解释变量x的散点图中,若随着x的增加,图中y散点分布的区域逐渐变宽,则随机项可能出现了()异方差。
A:递增
B:递减
C:复杂
D:同
正确答案:【递增
】
6、多选题:戈里瑟检验法的缺点有()。
A:结构函数过多,难以确定解释变量的适当的幂次
B:该方法可用于大样本,而在小样本中不适用
C:无法在更大的范围内寻找异方差性的结构函数。
D:需要进行大量计算,比较繁琐
正确答案:【结构函数过多,难以确定解释变量的适当的幂次
;该方法可用于大样本,而在小样本中不适用
;需要进行大量计算,比较繁琐
】
7、多选题:如果依然用OLS进行估计,以下()是异方差导致的后果。
A:变量的显著性检验失去意义
B:模型的预测失效
C:参数估计量的线性性和无偏性不再成立
D:参数估计量非有效
正确答案:【变量的显著性检验失去意义
;模型的预测失效
;参数估计量非有效
】
8、判断题:在存在异方差的情况下,普通最小二乘估计量的线性性和无偏性不会受到影响。()
A:错
B:对
正确答案:【对】
9、判断题:异方差之所以会产生,是因为数据处理方法有误,正确处理数据即可解决这一问题。()
A:对
B:错
正确答案:【错】
第五章 单元测试
1、单选题:模型存在自相关问题,是因为违背了经典线性回归模型关于()方面的假设。
A:随机误差项是正态分布的
B:随机误差项是同方差的
C:随机误差项是无序列相关的
D:随机误差项是零均值的
正确答案:【随机误差项是无序列相关的
】
2、单选题:杜宾-h检验法中,统计量表达式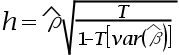 中,
中,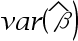 表示()。
表示()。
A:自变量滞后项OLS估计量的方差
B:所有因变量OLS估计量的方差和
C:所有自变量OLS估计量的方差和
D:因变量滞后项OLS估计量的方差
正确答案:【因变量滞后项OLS估计量的方差
】
3、单选题:一般情况下,对于实际经济金融问题,检验其自相关是否存在可以利用DW检验法,如果存在自相关问题,检验结果最常见的情形是()。
A:d统计量落在4-dL到4区间
B:d统计量落在0到dL区间
C:d统计量落在du到4-du区间
D:d统计量落在0到4区间
正确答案:【d统计量落在0到dL区间
】
4、单选题:绘制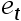 和
和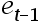 的散点图,
的散点图,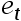 在纵坐标,
在纵坐标,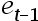 在横坐标。如果绘制出来的散点落在第一和第三象限,则随机项
在横坐标。如果绘制出来的散点落在第一和第三象限,则随机项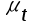 存在( )自相关。
存在( )自相关。
A:第一象限是负自相关,第三象限是正自相关
B:正
C:负
D:第一象限是正自相关,第三象限是负自相关
正确答案:【正
】
5、单选题:对于一阶线性自相关,自相关程度的度量运用了自相关系数,这体现了()之间的相关性。
A: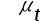 与
与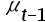
B: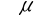 与Y
与Y
C:X与Y
D: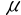 与X
与X
正确答案:【与
】
6、多选题:关于DW检验,以下哪些是它的使用局限()。
A:一般要求样本容量至少为15,否则很难对自相关的存在性做明确的结论
B:只适用于一阶线性自相关,对于高阶自相关皆不适用
C:无法用来判定通过原点的回归模型的自相关问题
D:不适合用于自回归模型
正确答案:【一般要求样本容量至少为15,否则很难对自相关的存在性做明确的结论
;只适用于一阶线性自相关,对于高阶自相关皆不适用
;无法用来判定通过原点的回归模型的自相关问题
;不适合用于自回归模型
】
7、多选题:如果依然用OLS进行估计,以下()是自相关导致的后果。
A:可能会导致t检验失效
B:可能会导致F检验失效
C:参数估计量的方差是有偏的
D:参数估计量非有效
正确答案:【可能会导致t检验失效
;可能会导致F检验失效
;参数估计量的方差是有偏的
;参数估计量非有效
】
8、判断题:BG检验适用范围更广泛,适用于高阶自相关的检验,这一点是DW检验很杜宾-h检验做不到的。()
A:错
B:对
正确答案:【对】
9、判断题:杜宾两步法第一步是先求得自相关系数,第二步和广义差分法一样。()
A:错
B:对
正确答案:【对】
10、判断题:当存在自相关的情况时,在小样本的情况下最小二乘估计量仍然是线性的和无偏的,但却不是有效的,但是在大样本的情况下是BLUE。()
A:错
B:对
正确答案:【错】
第六章 单元测试
1、单选题:在对模型的解释变量进行选择时,我们常用逐步回归法,即以Y为被解释变量,逐个引入解释变量X,构成回归模型,进行模型估计。如果在引入一个新解释变量后,模型的拟合优度显著提高,则说明新引入的变量是()。
A:其他解释变量可以替代的变量
B:可以被舍去的变量
C:一个独立解释变量
D:随机分布的变量
正确答案:【一个独立解释变量
】
2、单选题:在以下四个多重共线性修正方法中,难度最大、要求最高的方法是()。
A:利用先验信息法
B:补充新的数据
C:改变解释变量形式
D:删除不必要的变量
正确答案:【利用先验信息法
】
3、单选题:解释变量之间相关性越大,方差膨胀因子VIF越()。
A:小,但不会小于0
B:小
C:大
D:大,但不会大于1
正确答案:【大
】
4、单选题:如果在产生多重共线性的因素中有相对不重要的变量,则可试着将其删除,但会产生以下()新的问题。
A:当排除了某个或某些变量后,保留在模型中的变量的系数的经济意义将发生变化,其估计值也将发生变化
B:其他都是
C:被删除的变量对因变量的影响将会被其他解释变量和随机误差项所吸收
D:删除某个变量可能会导致模型设定误差
如有任何疑问请及时联系QQ 50895809